Consumers Read Product Descriptions and Reviews and Compare Features and Prices of Similar Products
Sentiment Analysis and Product Recommendation on Amazon's Electronics Dataset Reviews -Function 1
Part 1: Exploratory Data Analysis (EDA)
Introduction
The Internet has revolutionized the mode we buy products. In the retail eastward-commerce world of online marketplace, where experiencing products are not feasible. Also, in today'due south retail marketing world, there are and then many new products are emerging every day. Therefore, customers demand to rely largely on product reviews to make up their minds for better conclusion making on buy. Even so, searching and comparing text reviews can be frustrating for users. Hence nosotros need better numerical ratings system based on the reviews which will make customers purchase decision with ease.
During their conclusion making procedure, consumers want to find useful reviews as quickly every bit possible using rating system. Therefore, models able to predict the user rating from the text review are critically important. Getting an overall sense of a textual review could in plow improve consumer experience. Too, it can help businesses to increase sales, and improve the product by agreement client's needs.
The amazon review dataset for electronics products were considered. The reviews and ratings given by the user to different products as well every bit reviews about user's experience with the product(due south) were besides considered.

Problem Statement
The goal is to develop a model to predict user rating, usefulness of review and recommend most similar items to users based on collaborative filtering.
Information Collection
The electronics dataset consists of reviews and product information from amazon were collected. This dataset includes reviews (ratings, text, helpfulness votes) and product metadata (descriptions, category data, toll, brand, and image features).
Product Complete Reviews data
This dataset includes electronics product reviews such as ratings, text, helpfulness votes. This dataset was obtained from http://jmcauley.ucsd.edu/data/amazon/. The original data was in json format. The json was imported and decoded to convert json format to csv format. The sample dataset is shown below:
Each row corresponds to a customer review and includes the following variables:

Product Metadata
This dataset includes electronics production metadata such as descriptions, category information, toll, make, and image features. This dataset was obtained from http://jmcauley.ucsd.edu/data/amazon/. The json was imported and decoded to convert json format to csv format. The sample product meta dataset is shown below:
Each row corresponds to production and includes the following variables:

Data Wrangling
Merging Dataframes
Production reviews and meta datasets in json files were saved in different dataframes. Two dataframes were merged together using left bring together and "asin" was kept as common merger. Concluding merged data frame description is shown below:
In order to reduce time consumption for running models, just headphones products were chosen and the following method was adopted.
- Out of 1689188 rows, 45502 rows were null values in product title. Those rows were dropped.
- Dataset with product title named "Headphones", "Headphones", "headphones", "headphone" were extracted from merged dataframe. Final headphones dataset was 64305 rows (observations).
Handling Duplicates, Missing Values
- 22699 rows in brand cavalcade were observed as zippo values. To solve this, brand proper noun was extracted from title and replaced null values in brand.
- Dropped missing values in "reviewerName","cost","description","related" were dropped.
- "reviewText" and "summary" were concatenated and was kept under review_text characteristic
- Helpful characteristic was split into positive and negative feedback.
- Ratings greater than or equal to 3 was categorized every bit "good" and less than 3 was classified as "bad".
- Helpfulness ratio was calculated based on pos feedback/full feedback for that review
- Dropped duplicates based on "asin", "reviewerName","unixReviewTime". After dropping duplicates, the dataset consisted 61129 rows and 18 features.
- ReviewTime was converted to datetime '%m %d %Y format.
- Columns were renamed for clarity purpose.
Descriptive Statistics
The following summary statistics was obtained
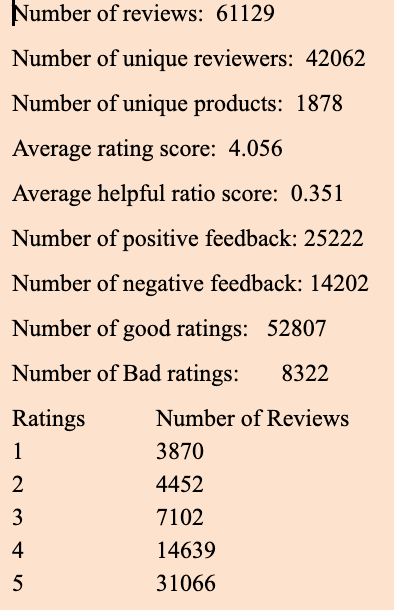
The summary statistics for headphones dataset is shown beneath:
Preprocessing Text
Since, text is the most unstructured form of all the available information, various types of noise are present in information technology and the data is non readily analyzable without any pre-processing. The entire procedure of cleaning and standardization of text, making it noise-gratis and ready for analysis is known equally text preprocessing. In this section, the post-obit text preprocessing were practical.
Removing HTML tags
HTML tags which typically does not add much value towards understanding and analyzing text. HTML words were removed from text.
Removing accented characters
Accented characters/letters were converted and standardized into ASCII characters.
Expanding Contractions
Contractions are shortened version of words or syllables. They exist in either written or spoken forms. Shortened versions of existing words are created by removing specific messages and sounds. In instance of English language contractions, they are ofttimes created by removing 1 of the vowels from the word.
By nature, contractions do pose a trouble for NLP and text analytics because, to starting time with, we accept a special apostrophe character in the word. Ideally, we can take a proper mapping for contractions and their corresponding expansions and and so use it to expand all the contractions in our text.
Removing Special Characters
One of import task in text normalization involves removing unnecessary and special characters. These may be special symbols or even punctuation that occurs in sentences. This step is often performed earlier or subsequently tokenization. The main reason for doing then is considering oft punctuation or special characters practise not have much significance when we analyze the text and utilize it for extracting features or data based on NLP and ML.
Lemmatization
The process of lemmatization is to remove word affixes to become to a base course of the word. The base form is also known as the root word, or the lemma, will always be nowadays in the lexicon.
Removing Stopwords
Stopwords are words that accept petty or no significance. They are usually removed from text during processing so as to retain words having maximum significance and context. Stopwords are unremarkably words that stop up occurring the most if you aggregated any corpus of text based on singular tokens and checked their frequencies. Words like a, the , me , and and so on are stopwords.
Building a Text Normalizer
Based on the functions which we have written above and with additional text correction techniques (such as lowercase the text, and remove the actress newlines, white spaces, apostrophes), we built a text normalizer in lodge to aid us to preprocess the new_text document.
After applying text normalizer to 'the review_text' document, nosotros applied tokenizer to create tokens for the make clean text. Every bit a result of that, nosotros had 3070479 words in total. Afterwards cleaning, we take 25276 observations.
A clean dataset volition allow a model to learn meaningful features and not overfit on irrelevant noise. After following these steps and checking for additional errors, we can showtime using the make clean, labelled data to train models in modeling department.
Exploratory Data Analysis (EDA)
After collecting data, wrangling data so exploratory analyses were carried out. The following insights were explored through exploratory analyses.
- Predicting ratings based on reviews
- Usefulness on large book of reviews
- Rating vs number of reviews
- Rating vs proportion of reviews
- Helpful proportion vs Number of reviews
- Rating vs helpfulness ratio
- Top 20 nigh reviewed products
- Lesser xx reviewed products
- Positive and negative words
- World cloud for dissimilar ratings, brand name etc
Top twenty Most Reviewed Brands
Top 20 To the lowest degree Reviewed Brands
Tiptop xx Virtually Reviewed Products
Most Positively Reviewed Headphone
The most positively reviewed product in Amazon under headphones category is "Panasonic ErgoFit In-Ear Earbud Headphones RP-HJE120-D (Orange) Dynamic Crystal Clear Audio, Ergonomic Comfort-Fit". This product had overall skillful rating more three.
How the in a higher place product will go up after some years?
The Panasonic earbud headphone had overall positive review from 2010 onwards. The distribution of rating over a flow of time is shown beneath. This production had overall good mean rating more than iv.
The discussion cloud from good rating reviews for the above product. It shows major insight in terms of sellers perspective. It indicates most of the positive customers agree with "great fit", "good toll" and least with "sound quality". Similarly, the discussion cloud from bad rating reviews for the to a higher place product. It indicates most of the customers agree with "poor quality" and "terrible audio". From the sellers perspective, this product needs to be updated with "better sound" and "quality" in order to go positive feedback from customers.
Almost Negatively Reviewed Headphone
The about negatively reviewed product in Amazon under headphones category is "My Zone Wireless Headphones". This product had overall bad rating less than 3.
How the above production will go upward afterwards some years?
My zone wireless headphone had overall negative review from 2010 onwards except 2012. The distribution of rating over a period of time is shown below. This product had overall bad mean rating of around two.5.
The word deject from good rating reviews for the above product is shown below. It shows major insight in terms of sellers perspective. It indicates most of the positive customers concord with "easy setup", "piece of work with Television set" and to the lowest degree concur with "work peachy". Similarly, the word cloud from bad rating reviews for the in a higher place product is shown below. It indicates most of the customers agree with "bombardment issue" and "horrible reception" and "static interference". From the sellers perspective, this product needs to be updated with "expert quality battery", "reception issue" and "static outcome" in order to get positive feedback from customers.
Which Rating got Highest Number of Reviews?
Customers have written reviews and ratings were given from 1 to 5 for headphones they bought from Amazon betwixt 2000 to 2014. The distribution and percentage of ratings vs number of reviews is shown below. Number of reviews for rating 5 were high compared to other ratings. Overall, customers were happy virtually the products they purchased. Almost 50% customers gave 5 rating for the products they purchased. Only 15% customers gave ratings less than 3.
The ratings were divided into two categories. The rating below 3 were classified as "bad" and the remaining ratings were grouped as "expert". The distribution of rating class vs number of reviews is shown beneath. It indicates most 50000 reviews were identified as good rating.
The distribution of ratings vs helpfulness ratio is shown below. It indicates that all ratings accept same helpfulness ratio.
Which Rating got Highest Number of Review Length?
Which Year has the Highest Number of Reviews?
Full review numbers for each twelvemonth is shown below. Number of reviews were low during 2000–2010. 2013 has the highest number of reviews.
Which Year has the Highest Number of Customers?
Total unique customers for each year is shown below. Number of unique customers were low during 2000–2010. 2013 has the highest number of customers.
Which Yr has the Highest Number of Production?
Total unique production numbers for each year is shown beneath. Number of unique products were low during 2000–2010. 2013 has the highest number of products.
Which Yr has the Highest Number of Product?
Except 2001, 'good ratings' percentage is progressing over eighty%. 2001 has the lowest good ratings with 69% overall. 'good ratings' percentage is ninety% in 2000. Every bit information technology might be seen in the graph, the overall expert rating is progressing between 81% and ninety% in headphones products.
Average Helpfulness of the Production
Distribution of Review Length
Which review length bin has the Highest Number of Proficient Rating?
As it might be seen below, the highest percentage of skillful rating reviews lies betwixt 0–1000 words with 96 % whereas lowest per centum of good rating review lies between 1700–1800 words with 80%. As the review length extends, the skilful rating tends to increase. Generally, the customers who have write longer reviews (more than 1900 words) tends to give skilful ratings.
Which review length bin has the Highest Number of Helpfulness Ratio?
As it might exist seen beneath, the highest helpfulness ratio lies between 0–1200 words with 0.viii whereas lowest helpfulness ratio lies between 1200–1300 words with 0.6. Equally the review length extends, the helpfulness ratio tends to increase. Generally, the customers who have write longer reviews (more than 1300 words) tends to have loftier helpfulness ratio.
The frequency of review length for helpfulness and unhelpfulness is shown beneath. It indicates that overall helpfulness and unhelpfulness ratio were the same for larger review length. Unhelpfulness ratio were high in instance of pocket-size length review.
Top Words for Good Rating?
The most mutual 50 words, which belong to skillful rating class, are shown beneath. Information technology shows the all good words from customers about the products.
Summit Words for Bad Rating?
Similarly, the almost common words, which belong to bad rating grade, are shown below. It shows all bad rating words from customers about the products.
Code:
Data Wrangling:
https://github.com/umaraju18/Capstone_project_2/hulk/master/code/Amazon-Headphones_data_wrangling.ipynb
EDA:
Part two: Sentiment Analysis and Product Recommendation
Source: https://towardsdatascience.com/sentiment-analysis-and-product-recommendation-on-amazons-electronics-dataset-reviews-part-1-6b340de660c2
0 Response to "Consumers Read Product Descriptions and Reviews and Compare Features and Prices of Similar Products"
Post a Comment