Upload Youtube Trending Video in Sql Code
YouTube Trending Video Analysis with SQL
How SQL can be used as a information analysis tool
SQL is a linguistic communication used for managing data in relational databases that store data in tabular form with labelled rows and columns. Nosotros query data from a relational database with the select statement of SQL. The select argument is highly versatile and flexible in terms of data transformation and filtering operations.
In that sense, SQL tin exist considered as a data assay tool. The advantage of using SQL for data transformation and filtering is that we only retrieve the information we need. It is more than practical and efficient than retrieving all the data and so applying these operations.
In this article, we will use SQL statements and functions to clarify YouTube trending video statistics. The dataset is bachelor on Kaggle. I created an SQL tabular array that contains a small role of this dataset.
Notation: I'chiliad using MySQL as the database management system. Although SQL syntax is mostly the same for all database direction systems, in that location might be small differences.
The table is called "trending" and it has the post-obit construction.
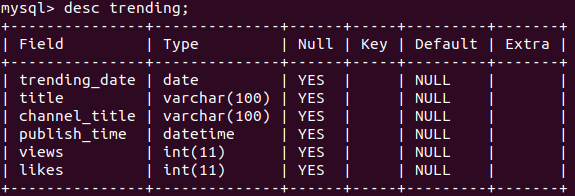
Nosotros have the dates a video is published and becomes trending. Nosotros also take the title and channel of the video. The views and likes are the other two features the dataset contains.
Regarding all these features (i.e. columns) we tin can practice a agglomeration of different operations. For instance, a simple one can be finding the elevation 5 channels in terms of the number of trending videos.
mysql> select channel_title, count(*) as number_of_videos
-> from trending
-> group by channel_title
-> order by number_of_videos desc
-> limit 5; +-----------------+------------------+
| channel_title | number_of_videos |
+-----------------+------------------+
| Washington Post | 28 |
| Netflix | 28 |
| ESPN | 27 |
| TED-Ed | 27 |
| CNN | 27 |
+-----------------+------------------+
We select the aqueduct championship column and count the number of rows. The "as" keyword is used to assign a new name to the aggregated columns. The group by clause is used to grouping the videos (i.e. rows) based on channels. Finally, we sort the results in descending club using the order past clause and display the first 5.
The number of videos seems to be besides low because I simply included the ones published in Jan, 2018.
We may want to see the title of the about-viewed video.
mysql> select title, views
-> from trending
-> where views = (select max(views) from trending); 
The query above contains a nested select statement. It is used with the where clause to find the desired condition which is the maximum values in the views column.
The about-viewed video in this table has been watched most 60 million times.
SQL provides many different options for filtering the data. In the previous example, we found out that the well-nigh-viewed video belongs to Bruno Mars. We tin can filter the titles to but see the videos belong to Bruno Mars.
mysql> select distinct(title)
-> from trending
-> where title like "%Bruno Mars%"; 
Nosotros practice not have to provide the verbal value for filtering if we use the like keyword. The "%" represents whatever character so "%Bruno Mars%" represents any value that contains the "Bruno Mars" phrase. The singled-out keyword is used to remove the duplicates.
If nosotros are non sure about characters existence lower or uppercase, we can convert all the characters to lower or upper instance earlier filtering.
mysql> select singled-out(lower(title))
-> from trending
-> where title similar "%bruno mars%"; 
The dataset contains the published engagement of videos and when they become trending. Nosotros can calculate the boilerplate time it takes for a video to become trending.
Before calculating the difference, we need to extract the date function from the publish time cavalcade because it contains both the date and time.
mysql> select trending_date, publish_time
-> from trending
-> limit 3;
+---------------+---------------------+
| trending_date | publish_time |
+---------------+---------------------+
| 2018-01-02 | 2018-01-01 xv:30:03 |
| 2018-01-02 | 2018-01-01 01:05:59 |
| 2018-01-02 | 2018-01-01 14:21:xiv |
+---------------+---------------------+ The appointment function extracts the engagement part and the datediff function calculates the departure. Thus, we can summate the average difference as follows:
mysql> select avg(datediff(trending_date, appointment(publish_time)))
-> as avg_diff
-> from trending; +----------+
| avg_diff |
+----------+
| 3.9221 |
+----------+
The datediff functions takes two dates separated past a comma and calculates the difference. It takes 3.92 days on average for a video to become trending.
We can also calculate the average difference for videos that are published in a specific time period. We just need to add a where clause for filtering.
mysql> select avg(datediff(trending_date, date(publish_time))) equally avg_diff
-> from trending
-> where hour(publish_time) > 20; +----------+
| avg_diff |
+----------+
| four.4825 |
+----------+
Nosotros extract the hour value from publish fourth dimension and use it in the where clause for filtering.
SQL provides functions for data assemblage which can be implemented in the select statement. For example, nosotros tin calculate the average ratio of likes over views of videos published by Netflix.
mysql> select avg(likes / views)
-> from trending
-> where channel_title = "Netflix"; +--------------------+
| avg(likes / views) |
+--------------------+
| 0.01816295 |
+--------------------+
The average value is close to 0.02 so Netflix videos accept approximately 2 percent like over view ratio.
Permit's write a slightly more complicated query and calculate the boilerplate video views of channels that published more than than 25 videos. Nosotros will also sort the results in descending guild by the averages.
mysql> select channel_title, avg(views) as avg_views,
-> count(title) as number_of_videos
-> from trending
-> group by channel_title
-> having number_of_videos > 25
-> order by avg_views desc; 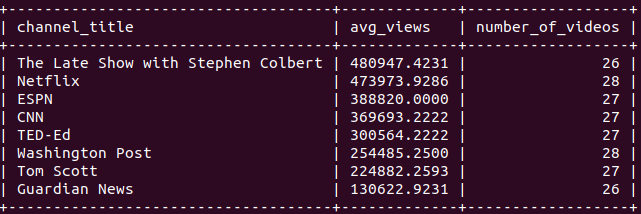
The retrieved data contains 3 columns. One is the channel title cavalcade and the other 2 are aggregated columns. We filter the channels based on the number of videos.
You may have noticed that nosotros used the "having" clause instead of the "where" clause for filtering. The "having" clause is used for filtering based on aggregated columns.
Conclusion
We have done some examples to analyze the YouTube trending video statistics. The examples clearly demonstrate that SQL can besides exist used as a data assay tool.
I recollect SQL is a required skill for data scientists or analysts. Nosotros should at least know how to query a relational database. Complex queries that perform data transformation and manipulation operations while retrieving the data have the potential to save memory. They also ease the tasks that need to be done afterward.
Thank you for reading. Please let me know if you have any feedback.
Source: https://towardsdatascience.com/youtube-trending-video-analysis-with-sql-b022993d0e94
0 Response to "Upload Youtube Trending Video in Sql Code"
Post a Comment